The future of black box optimization benchmarking is procedural
February 16, 2025
This blogpost discusses a recent position paper by Saxon et al. called Benchmarks as Microscopes: a Call for Model Metrology. The authors argue that the benchmarks we construct ought to be constrained, dynamic, and plug-and-play. I’ll dive deeper into what each of these words mean, and I’ll argue that researchers in Procedural Content Generation (PCG) are in an ideal position to construct such benchmarks.
Saxon et al.’s paper focuses on Natural Language Processing and language models, but I think their arguments translate well to my domain: black box optimization.
With this blogpost I try to bridge the fields of black box benchmarking and PCG, encouraging PCG researchers to take a look into benchmark construction for black box optimization and other fields (becoming what Saxon et al. call model metrologists).
Since the goal is to bring people from different fields together, I won’t assume you have knowledge on black box optimization nor PCG. If you’re already familiarized with these ideas, feel free to skip the sections that introduce said topics.
The name of the game: black box optimization #
Think of a black box function as any process that transforms a set of inputs \(x_1, x_2, \dots, x_d\) into a real number \(r = r(x_1, \dots, x_d)\) .
This definition is vague on purpose, and allows us to define several things as black box functions. Two examples: when you log into Instagram, the app that you are shown is “parametrized” by several \(x_i\) variables such as, for example, \(x_1\) could be whether your reels are shown in a loop or just once, \(x_2\) could be the person you first see on your timeline, and \(x_3\) could be how often you’re shown an ad.1 One example of a metric \(r(x_1, x_2, x_3)\) would be how long you spend on the app. Another less macabre example is making a recipe for cookies, with the different \(x_i\) s being ingredient amounts, and the result being a combination of how tasty it is compared to the original recipe.2
More formally, black boxes are mappings \(r\colon\mathcal{X}\to\mathbb{R}\) from a search space \(\mathcal{X}\) (which may be fully continuous, discrete, or a combination of both) to a real number. What makes it a black box (say, compared to other types of functions) is that we don’t have access to anything beyond evaluations. In other types of mathematical functions, we usually have them in a closed form.
Another idea that we usually attach to black boxes is that evaluating them is expensive and cumbersome. Cooking a batch of cookies might not sound like much but, in other applications, getting the feedback, reward or cost \(r(x_1, x_2, \dots, x_d)\) might take days, or involve using assets that are incredibly expensive. Think for example of a chemical reaction involving scarse and expensive solvents, or training a large Machine Learning model for several days on sizeable compute.
The goal, then, is to optimize the black box. We want to find the values of \(x_1, \dots, x_d\) that maximize (or minimize) the signal \(r(x_1, \dots, x_d)\) . We want to find the recipe for the tastiest cookies, and Meta wants to keep us on Instagram as long as possible. The lack of a closed form for our signal \(r\) renders unavailable all the usual mathematical optimization techniques that are based on convexity, gradients, or Hessians, which means that we need to come up with alternatives that rely only on evaluating the function.3
Black box optimization is everywhere nowadays. This framework is generic enough to allow us to express several processes as black boxes to be optimized. There’s plenty of contemporary work on this, with applications ranging in fields as diverse as self-driving labs, molecule and protein design for therapeutical purposes, hyperparameter tuning and automatic Machine Learning.
Benchmarking in black box optimization #
Just so we are all in the same page, let’s define what a benchmark is. To me, a benchmark is a collection of problems in which a given system or model is tested. The performance of a model is gauged by a collection of metrics, for example
- classification accuracy in image recognition,
- number of correctly answered questions in a standardized test (e.g. the BAR) in language modelling,
- prediction error with respect to the solutions of a differential equation in scientific ML, and
- prediction error on the properties of mutated proteins in structural biology.
In the case of black box optimization, it’s common to start benchmarking on a family of synthetic functions for optimization, and the metric that we use to check whether we are doing well is e.g. how quickly we’re finding the maximum/minimum of the function (or how close we get to finding it), with a metric called regret, defined mathematically as the distance to the optimal value.
Although they have a closed form (which is slightly contradicting our definition of a black box), their form is designed to mimic certain behaviors that we might expect from real black boxes out there: multiple local minima/maxima, useless gradient information, needle-in-a-haystack-type problems… As an example of this, here are the plots of how Rastrigin and Lévi (two common examples) look in the 2D case: Notice how Rastrigin has several local minima, meaning that derivative-based methods would easily get stuck on local minima, and also notice how one of the dimensions of Lévi (Y) isn’t as important as the other (X). These are properties we may also expect of real-world black boxes.
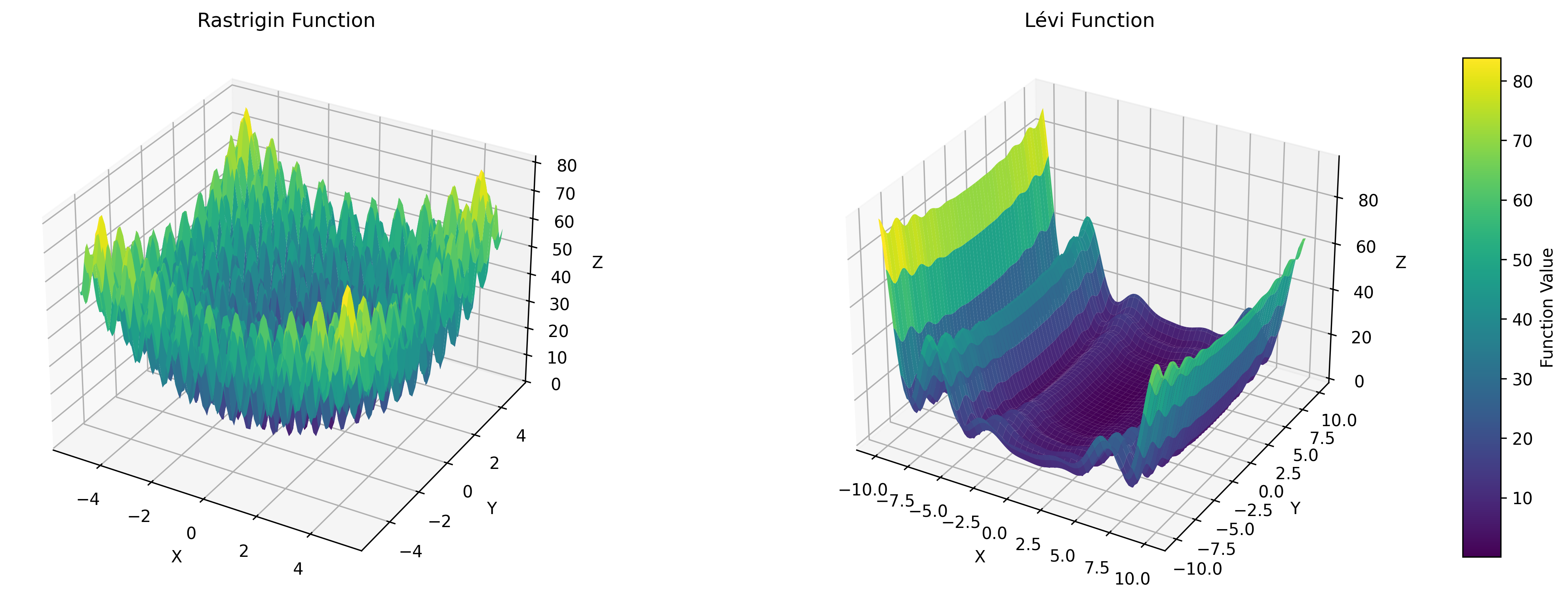
Two commonly-used synthetic black boxes for continuous optimization.
We, as a community, have devoted a significant efforts on keeping track of the performance of our optimizers on these synthetic benchmarks. Check any paper on black box optimization, and you will always find regret plots with performance on these.4 There are even entire platforms dedicated to measuring the performance of black box optimizers on these synthetic functions. An example of such is Hansen et al.’s COmparing Continuous Optimizers (COCO).
I would like to argue that our efforts are better spent doing something different. The goal of these synthetic functions is, allegedly, to give us proxies for real-world optimization tasks, but we don’t know how the real world is until we face it. These synthetic black box functions (as well as many other benchmarks in black box optimization for chemistry or biology) fall short when describing the potential of an optimizer in a given real-world task.
The current state of our benchmarking is such that, when a practitioner arrives with an interesting problem to optimize, we don’t have much to show, and we can’t confidently assess which algorithms would perform best in their problems. Best we can say is which algorithms perform well on highly synthetic, general sets of examples.5
Model metrology (or best practices for benchmarking) #
Saxon et al. gave me the language to formulate exactly what we are doing wrong: these benchmarks are too general, and we should be constructing specialized, constrained problems to test our optimizers, focusing on what a given practitioner needs. Moreover, our benchmarks are static (i.e. they’re the same over time), and thus we run the risk of overfitting to them.6 We need dynamic benchmarks. One aspect that we have nailed, though, and that we should keep in future iterations is that our benchmarks are easily deployable, or plug-and-play.
These are the three keywords they claim make good benchmarks. Good benchmarks are
- constrained, bounded and highly specific to a given application,
- dynamic to avoid overfitting to certain behaviors, and
- plug-and-play, easy to deploy.
The authors call for a new research field, entirely devoted to evaluating model performance, called model metrology. A model metrologist is someone who has the tools to create such constrained, dynamic & plug-and-play benchmarks, tailored to the needs of a given practitioner.
Procedural Content Generation… #
…stands for the use of algorithms to generate content. It has plenty of use in video games, where PCG allows developers to generate assets for their games (from the clothes a character wears, to the entire game map). Several block-buster games use PCG as a core mechanic. For example, the whole world one explores inside Minecraft is procedurally generated from a random seed; another example is No Man’s Sky, where an entire universe is created procedurally using an algorithm that depends only on the player’s position.

An image from No Man's Sky, taken from their press release. A whole universe made procedurally.
PCG is also a research field, in which scholars taxonomize, study and develop novel techniques for generating content.7 Some of them involve searching over a certain representation of game content (e.g. describing a dungeon game as a graph of connected rooms, and searching over all possible graphs of a certain size), other involve exploring formal grammars that define game logic/assets, and most of them use randomness to create content. In Minecraft, the whole world is made using random number generators.
Researchers in PCG are in an ideal position to create constrained, dynamic & plug-and-play benchmarks. If we can formulate benchmarks as pieces of content, we could leverage plenty of research in the PCG community. They already have a language for developing content, measuring e.g. the reliability, diversity and controlability of their developments. We just need to convince them to work on building synthetic benchmarks for us according to the specific needs of a set of practitioners.
Towards procedural benchmark generation #
We could think of creating a novel subfield of model metrology: procedural benchmark generation. PCG researchers could start by establishing contact with practitioners in black-box optimization and, together with the model metrologists of said domain, they could establish the requirements that the developed benchmarks would need to meet.
Afterwards, it’s all about procedural generation: cleverly combining algorithms that rely on randomness (or grammars, or useful representations followed by search, or any other PCG technique) to create a procedurally generated benchmark. This process of generating benchmarks could then be evaluated using all the language we have for content: is it diverse enough? Can we control it? Does it express the desired behaviors? Are the resulting benchmarks a believable proxy of the actual task? Is generation fast?
Let me explain further what I mean by this with a recent example. It shows how procedural generation can be applied to constructing black boxes that are relevant for specific domains.
Example: closed-form test functions in structural biology #
Let me introduce you to the wonderful world of protein engineering.8 The set-up goes like this: one starts with a discrete sequence of amino acids \((a_1, \dots, a_L)\) called the wildtype, and the goal is to find slight deviations from this wildtype such that a signal \(r\) (for example thermal stability, or whether the protein binds well to a certain receptor in the body) is optimized.
An example of a protein (a tiny bit of DNJA1), which is a sequence of amino acids: Thr-Thr-Tyr-Tyr-Asp-... Each of these can be mutated with the aim of maximizing thermal stability or any other biophysical or medicinal property.
Nowadays, computing such signals is not straightforward. The state-of-the-art at time of writing is using huge Machine Learning models to get estimates of binding scores (AlphaFold 2, as an example), or using physical simulators. These are not easy to set-up, and much less query: one needs to install licensed software, have decent amounts of compute, and have the patience to wait for more than a minute per black box call.9 In the language of Saxon et al., these black boxes are not plug-and-play.
In 2024, Stanton et al. published a paper called Closed-Form Test Functions for Biophysical Sequence Optimization Algorithms. In it, they identify this lack of plug-and-play black boxes in protein design, and propose a black box that mimics the relevant behavior of the signals \(r\) described above, while being trivial to query.
The authors set out to create a black box that is
- Evaluated on discrete sequences and their mutations, which may render feasible or unfeasible sequences.
- Difficult enough to optimize, mimicking some second-order interactions (epistasis) that are usually present in protein design.
- Instant to query.
To do so, the authors propose Ehrlich functions, a procedurally generated black box based on a Markov Decision Process (MDP) to generate a “feasibility distribution” over the space of amino acids, and a set of motifs that needs to be satisfied in the sequence. Both the MDP and motifs are constructed at random.
When I first read this paper, I felt as if I was reading a PCG article: The authors propose a procedurally generated black box, which relies on randomness to create a set of conditions that need to be satisfied to score a discrete sequence. Almost as if they were creating a ruleset for a game. Funnily, some of their parameters (the quantization, for example) can be understood as increasing the difficulty of the game.
This, to me, is a first example of how procedural benchmark generation could look like. We could then investigate whether Ehrlich functions are indeed representative of the issues of protein sequence design, and whether Ehrlich functions are diverse, controllable, etc.
Conclusion #
Saxon et al. call attention to the fact that, quote, “Benchmarks can aim for generality—or they can be valid and useful”. I agree. And even though they raise their point in the context of evaluating language models, the lessons translate well to black box optimization (where we have been devoting significant resources to optimizing synthetic benchmarks).
I argue that benchmarks and black boxes can be thought of as a form of content, and that we could in the future leverage all the language that has been developed for Procedural Content Generation in the context of video games. In other words, PCG researchers could be great model metrologists and benchmark developers. A recent example can be found in biology, where a procedurally generated black box is a useful replacement for expensive simulators that are difficult to set-up.
-
These are just examples, of course. ↩︎
-
This is the canonical example of black box optimization, and Google actually did this once. ↩︎
-
In Algorithms for optimization by Kochenderfer and Wheeler, this type of optimization is called direct optimization. It has a pretty long history. Check Chap. 7 in their book for a longer introduction on the classics of the field. ↩︎
-
Check for example Fig 2. in the SAASBO paper, or Fig. 5 in the Vanilla BO paper. ↩︎
-
This is not entirely true. On one hand, there are several data-driven proxies for tasks in biology, chemistry, material science… On the other, we can tell practitioners to use tools for automatic selection of optimizers. There’s at least plenty of research on making dynamic tools for black box optimization, with plenty of progress on packages like nevergrad or Ax. If you’re interested in this line of thinking, check Carola Doerr’s current and future work. ↩︎
-
I’ve heard from two researchers in the field that one optimizer was performing surprisingly well in several benchmarks, optimizing them instantly… it turned out that the optimizer started by proposing the origin point \((0, 0, \dots, 0)\) , which is coincidentally the optima location for several of these black boxes. ↩︎
-
If you want to learn more, check the PCG book by several researchers in the field. ↩︎
-
If you’re a biologist, you’ll cringe at my description. I’m talking here about ab initio protein engineering, where one starts from a wildtype. There’s also de novo protein design, where one creates sequences of amino acids “from nothing”. An example of de novo design is the Chroma paper. ↩︎
-
And that’s why, in my previous job, we tried to develop a Python framework for democratizing access to some of these black boxes. It’s called poli. ↩︎